MirageJS: Choosing the right Serializer

Min Kim
August 31, 2020

MirageJS is one of the pioneers in enabling frontend developers to use mocks systematically for their tests and development. It was originally built for Ember.js in 2015, but due to its popularity the maintainers created a standalone version compatible with any javascript framework.
Mirage introduces itself as a mocking library, but at Frontside we don't think that's a good enough term to refer to its extensive power. If your application uses a RESTful API (an adapter for GraphQL is on the way), Mirage is a great choice to simulate your backend with high-fidelity outputs. We've used Mirage in several projects to enable frontend developers to keep advancing the UI while the backend is not yet ready. Its flexibility also makes it a perfect test companion compatible with many tools out there, including Cypress.
A key element of Mirage that enables it to generate realistic responses lies on its serializer layer. The serializer takes the data stored in Mirage's seeded database and outputs it in the format that you configure for it. For an effective simulation strategy, you want that output format to match exactly your backend API specifications.
In this article, we'll explore the four serializers available on Mirage by default. Choosing which one is the right one for you depends on your API formats. There might be a serializer that works with your backend right out of the box or you may have to customize it from a base. After outlining how the serializer layer works in Mirage, we'll dive into the specifics of each one.
How Mirage Serializers Work
Understanding how Mirage’s various serializers work begins with reviewing how data flows thought Mirage. At the most basic level, Mirage allows you to create mocks in a traditional way, returning hand-crafted objects:
this.get("/blog-posts", () => {
return [
{ id: "1", title: "Beyond mocking" },
{ id: "2", title: "A lesson about Interactors" },
{ id: "3", title: "Github Actions: all about pull_request" },
];
})
However, hand-crafted anything is not a scalable solution, and these sorts of objects become difficult to maintain when your data relies on relationships.
Instead, we recommend taking advantage of Mirage modeling and ORM capabilities so you can shape your backend in Mirage and seed it with generated data. As the snipped code below illustrates, you can use the seeded models of the database directly from your route handle:
this.get("/users", (schema, request) => {
return schema.users.all()
})
In this case you don't have to manually deal with IDs, formats, or the concrete user records. Instead, you use a schema query that will bring records (based on models and factories) from Mirage's database and output the format that your backend uses.
In order to do that, you have to set up models, factories, and serializers in Mirage. Models deal with the relationship between records, factories generate sample data for the records' attributes, and serializers format how the records will be mapped in a JSON response. The following diagram illustrates how these pieces come together to enable you to query records in your Mirage route handles:
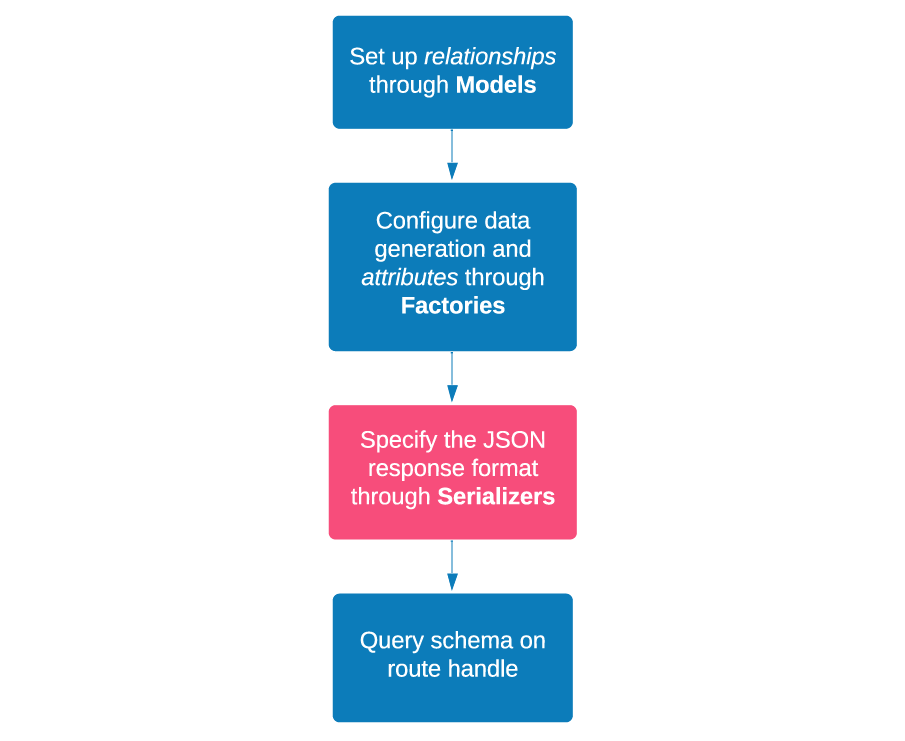
The role of the serializer is to map the data to a JSON structure that matches your backend needs. The structure of the JSON refers to how the object keys are named and what's nested inside which keys.
Given that the serializer's main purpose is to make it easy for you to have Mirage outputting realistic data for your frontend, we recommend discussing with your backend team how they plan to format the responses from their endpoints. Then you can compare those responses to what the different Mirage serializers offer and choose the closest one, customizing it if necessary.
Model and Factories Setup
The job of a serializer is to provide a format that represents the attributes and relationships of the records stored in Mirage’s database. To illustrate how the different serialiser options work, in this section we’ll describe a hypothetical set up. It’s worth noting at the outset that in Mirage models only describe relationships, not attributes; that means attributes can be defined arbitrarily when the model is instantiated in a factory.
In the code below we’ll use three models to describe the relationships among our data:
models: {
author: Model.extend({
blogPosts: hasMany(),
}),
blogPost: Model.extend({
author: belongsTo(),
post_blogComments: hasMany()
}),
post_blogComment: Model.extend({
blogPost: belongsTo()
})
}
Notice the inconsistencies in case and separators in the names for the model’s fields. We've used arbitrary casing so the effect of the serializers described below is more apparent.
Now for the factories, we’ll set them as described below. As we mentioned earlier, it’s in this part where the attributes for our records are declared:
factories: {
author: Factory.extend({
author_emailAddress: () => faker.internet.email()
}),
blogPost: Factory.extend({
blogPost_title: () => faker.random.words(3)
}),
post_blogComment: Factory.extend({
comment_paragraph: () => faker.random.words(6)
}),
}}
Again, to highlight the effects of serializers on the attribute names, notice that in the code above the casing for each attribute is mixed. You can see we're using a library called faker to generate random data to populate the models attributes.
To make the outputs comparable across serializers, the example responses that we provide are the result of fetching a request for all blogPosts:
schema.blogPosts.all( )
Data attributes on all serializers
Before getting into the specific serializers, let’s address first a peculiarity about attributes that all Mirage serializers share. As it turns out, Mirage doesn’t serialize all the attributes of a response evenly.
When we fetch all the blog posts with schema.blogPosts.all( ) we'll get all the records for blogs posts. If we configure the serializer to include relationships, we can expect the authors and comments from such blog posts too. The following diagram illustrates the relationships between blog posts, authors, and comments.
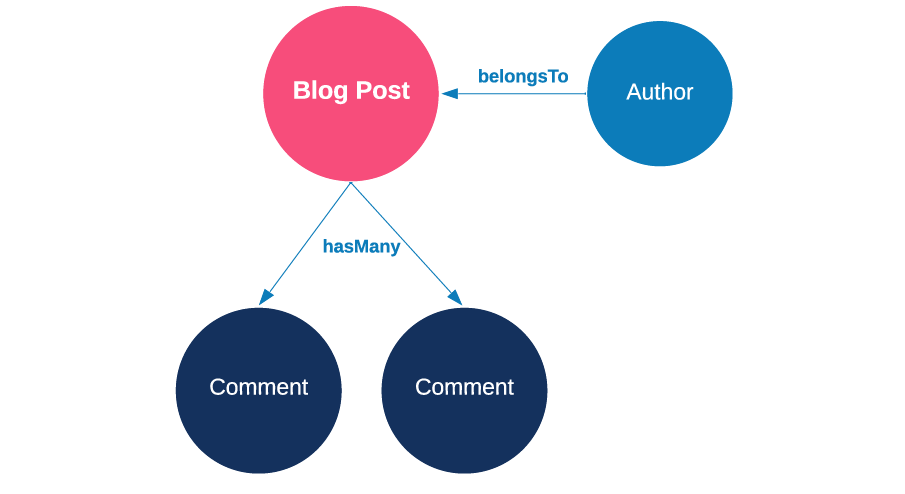
Because we’re using schema.blogPosts.all( ) to get these blog posts, we’ll say that blog posts are the queried records. As mentioned, included in that response we’d have the author of the blog post (through belongsTo). Additionally, we’ll get the blog post comments (through hasMany).
Serialization on queried records: attribute names are transformed
Serializers will only transform the attribute names of the queried records. The transformations applied vary from serializer to serializer; you’ll find the specifics in the sections below.
Records from belongsTo: attribute names are not transformed
Counterintuitively, the serializers in Mirage will not apply any transform to the attribute names of the records coming from a belongsTo relationship. This means that the inconsistent attribute name we included in our authors factory will remain as it was declared, author_emailAddress no matter which serializer you use.
Records from hasMany: attributes are not included
Perhaps to avoid loading large amounts of data, Mirage does not include the attributes of any record that has been loaded due to a hasMany relationship. This means that although we’ll get a list of the comments associated to the blog post we queried, we will not be able to get any of their attributes.
JSON API Serializer
This serializer follows the JSON API specification. A fetch for blogPosts with this serializer will return the following response format:
{
"data": [
{
"type": "blog-posts",
"id": "1",
"attributes": {
"blog-post-title": "A blog post"
}
"relationships": {...}
},
...
],
"included": [...]
}
Field names format: dashes
In compliance with JSON API conventions, all field names are changed to use dashes. As you can see in the example, the names that were inconsistently cased are all dasherized now; for instance, blogPost_title becomes blog-post-title.
Response structure: fixed top level elements
There are two top level keys for the JSON API response: data and included.
The main part of the response is data, an array of entries that answer to the query issued. In this case, it's providing all the blog posts available.
The other key, included will have the record information from the references related to the entries in data. By default, included is empty on Mirage.
Relationships: reference objects
Each record on data can have a relationships key. In our example, the blog post belongsTo an author and hasMany blog post comments. By default, the relationships are not included in Mirage by the JSON API serializer.
To include the relationships, we can configure the include option in the JSON API serializer. In that case, we'll get a relationships key inside each record from data with references to what those authors or comments are.
Below you can see how a single record looks like when the relationship references are included:
{
"type": "blog-posts",
"id": "1",
"attributes": {
"blog-post-title": "A blog post"
},
"relationships": {
"author": {
"type": "authors",
"id": "5"
},
"post-blog-comments": {
"type": "post-blog-comments",
"id": "5"
}
}
}
Notice that in JSON API Serializer, types are all dasherized and pluralized, and that they are used in every record. For instance, a single author has a type authors.
Additionally, all the records referenced in all the relationships key will be loaded in the included key of the response.
Alternatively, we can set the alwaysIncludeLinkageData option to true on the JSON API serializer, with which we'd get the relationship information on the data records, but those related records will not be included in the include array.
More details
Active Model Serializer
Active Model is the standard format for Rails APIs responses. Chances are if you don't already know whether or not you need to use this serializer, you most likely don't need this one. But let's still have a look at how this one handles its response. We'll be evoking the same fetch as the one we used for the JSON API Serializer. This is how the response with the Active Model Serializer would look:
{
"blog_posts": [
{
"id": "0",
"blog_post_title": "A blog post",
"author_id": "...",
"post_blog_comments_ids": [...]
}
]
}
Field names format: under_scored
The Active Model Serializer changes the caps to be under_scored no matter how the original model name was configured. As you can see in the example, the attribute names that were inconsistently cased are all under_scored now; for instance, blogPost_title becomes blog_post_title.
Response structure: top level types
The Active Model Serializer presents the entity types on the top level arrays, where the type name is pluralized. Unlike the JSON API Serializer the data is not nested under data or included objects. You can think of the response having lists of records grouped by type on the top level. In this example, blog_posts is the type of the queried objects and it's at the top level.
Relationships: _id suffixed reference (or embedded)
By default, relationships are not resolved for this serializer. However, we can configure the include option for the Active Model Serializer and then we'll receive them as references but in a different format than JSON API.
If include is configured, the records of the related fields in a relationship are also loaded at the top level of the JSON with their type names. In the target object, the reference to that related object is only an id.
The field name of the relationship will be appended _id:
{
"blog_posts": [
{
"id": "1",
"author_id": "5"
}
],
"authors": [
{
"id": "5",
"name": "Mika"
}
]
}
Additionally, you can decide to configure the embed option to nest the relationship object instead of having a reference:
{
"blog_posts": [
{
"id": "1",
"author": {
"id": "5",
"name": "Mika"
}
}
]
}
More details
Rest Serializer
The Rest Serializer is almost identical to the Active Model Serializer except that it transforms names to camelCase instead of under_score. Let's look at the example output for Rest Serializer:
{
"blogPosts": [
{
"id": "0",
"blogPostTitle": "A blog post"
"author": "...",
"postBlogComments": [...]
}
]
}
Field names format: camelCase
The Rest Serializer changes the caps to use camelCase no matter how the original attribute name was configured. As you can see in the example, the names that were inconsistently cased are all camelCased now; for instance, blogPost_title becomes blogPostTitle.
Response structure: top level types
The Rest Serializer presents the entity types on the top level, in the same way Active Model Serializer does: the top level keys are pluralized camelCase types. Relationships: no-suffix id reference (or embedded)
By default, relationships are not resolved for this serializer. However, we can configure the include option for the serializer and then we'll receive them as references.
If include is configured, the records of the related fields in a relationship are also loaded at the top level of the JSON with their type names. In the target object, the reference to that related object is only an id. The field name of the relationship will not be suffixed with anything:
{
"blogPosts": [
{
"id": "1",
"author": "5"
}
],
"authors": [
{
"id": "5",
"name": "Mika"
}
]
}
Additionally, you can decide to configure the embed option to nest the relationship object instead of having a reference:
{
"blogPosts": [
{
"id": "1",
"author": {
"id": "5",
"name": "Mika"
}
}
]
}
More details
Serializer
Last but not least is the barebone Serializer which MirageJS describes as basic. Its behavior is quite similar to Rest Serializer, with the only difference lying in how the relationship references are suffixed.
Let's check out the output for Serializer:
{
"blogPosts": [
{
"id": "1",
"blogPostTitle": "A blog post"
"authorId": "...",
"postBlogCommentsIds": [...],
}
]
}
Field names format: camelCase
This serializer changes the caps to use camelCase, no matter how the original attribute name was configured. As you can see in the example, the names that were inconsistently cased are all camelCased now; for instance, blogPost_title becomes blogPostTitle.
Response structure: top level types
The Serializer presents the entity types on the top level, in the same way Active Model Serializer does: the top level keys are pluralized camelCase types.
Relationships: Id suffix reference (or embedded)
By default, relationships are not resolved for this serializer. However, we can configure the include option for this serializer and then we'll receive them as references.
If include is configured, the records of the related fields in a relationship are also loaded at the top level of the JSON response with their type names. In the target object, the reference to that related object is only an id.
The field name of the relationship will be appended Id:
{
"blogPosts": [
{
"id": "1",
"authorId": "5"
}
],
"authors": [
{
"id": "5",
"name": "Mika"
}
]
}
Additionally, you can decide to configure the embed option to nest the relationship object instead of having a reference:
{
"blogPosts": [
{
"id": "1",
"author": {
"id": "5",
"name": "Mika"
}
}
]
}
More details
Cheat sheet
| JSON API Serializer | Active Model Serializer | Rest Serializer | Serializer | |
|---|---|---|---|---|
| Response structure | Top level | Top level keys by pluralized type_name. | Top level keys by pluralized typeName | Top level keys by pluralized typeName |
| Casing transforms | dasherized | under_score | camelCase | camelCase |
| Relationships included in response? | No, unless include is configured. Option for alwaysIncludeLInkageData | No, unless include is configured | No, unless include is configured | No, unless include is configured |
| Relationship reference in record |
| Name of attribute suffixed with _id ex: "author_id": "5" | Name of attribute with no suffic ex: "author": "5" | Name of attribute suffixed with Id ex: "authorId": "5" |